CrisisFACTS
CrisisFACTS is an open data challenge for state-of-the-art temporal summarization technologies to support disaster-response managers' use of online data sources during crisis events.
2023 TREC CrisisFACTS Track
Tracking developments in topics and events has been studied at TREC and other venues for several decades (e.g., from DARPA’s early Topic-Detection and Tracking initiative to the more recent Temporal Summarization and Real-Time Summarization TREC tracks). Today’s high-velocity, multi-stream information ecosystem, however, leads to missed critical information or new developments, especially during crises. While modern search engines are adept at providing users with search results relevant to an event, they are ill-suited to multi-stream fact-finding and summarization needs. The CrisisFACTS track aims to foster research that closes these gaps.
CrisisFACTS is making available multi-stream datasets from several disasters, covering Twitter, Reddit, Facebook, and online news sources gathered from the NELA News Collection. We supplement these datasets with queries defining the information needs of disaster-response stakeholders (extracted from FEMA ICS 209 forms). Participants’ systems should integrate these streams into daily lists of facts, which we can aggregate into summaries for disaster response personnel.
Jump to:
Overview
This track’s core information need is:
What critical new developments have occurred *today*
that I need to know about?
Many pieces of information posted during a disaster are not essential for responders or disaster-response managers. To make these needs explicit, we have made a list of general and disaster-specific queries/”user profiles”, available here. These queries capture a responder might consider important, such as the following:
- Emerging/approaching threats
- Changes to affected areas
- Changes to damage assessments
- Critical needs, such as food, water or medicine
- Damage to key infrastructure, evacuations, or emerging threats
- Progress made and accomplishments by responders
- Statistics on casualties or numbers missing
- Risks from hazardous materials
- Restriction on or availability of resources
- Weather concerns
Responders typically want to receive a summary of this information at regular intervals during an emergency event. Stakeholders current fulfill these information needs via manual summarization, e.g., by filling daily incident reports such as the FEMA ICS 209 forms.
2023 Tasks – Fact Extraction for Downstream Summarization
As in 2022, the main 2023 task focuses on fact extraction, where systems consume a multi-stream dataset for a given disaster, broken into disaster-day pairs. From this stream, the system should produce a minimally redundant list of atomic facts, with importance scores denoting how critical the fact is for responders. CrisisFACTS organizers will aggregate these facts into daily summaries for these disasters, along the following lines:

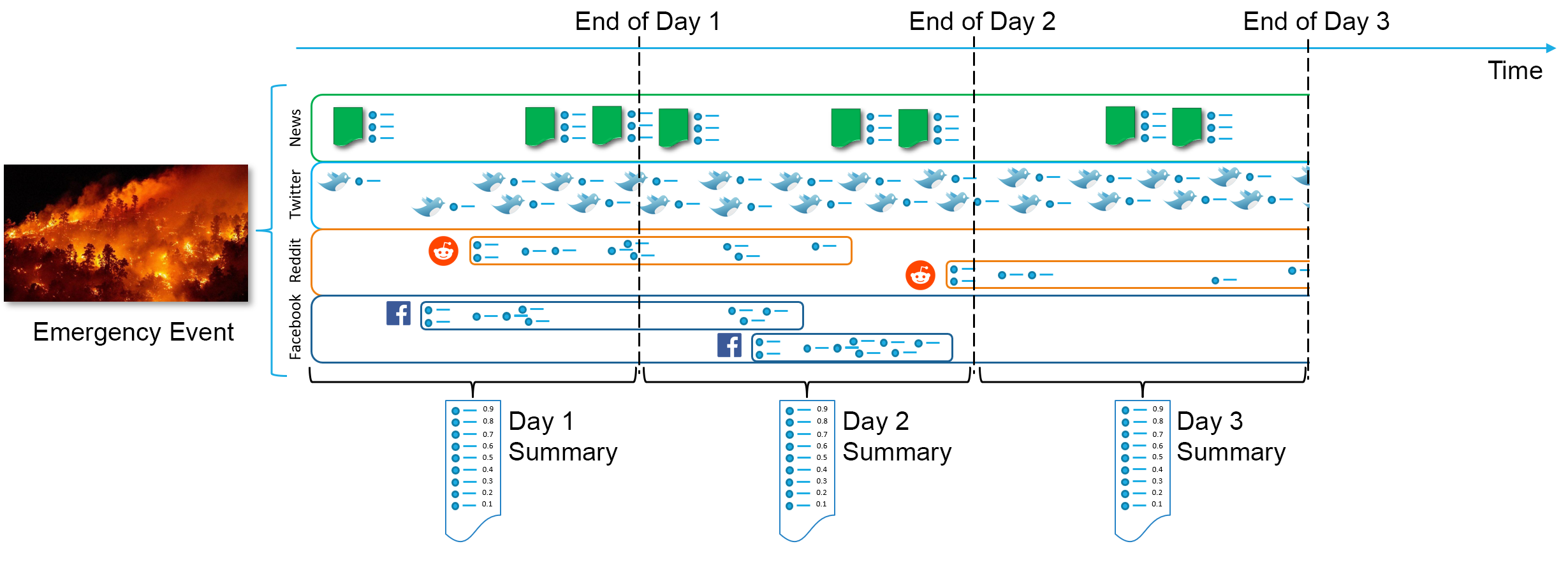
Fig 1. ConOps/High-Level System Overview
System Input
Input to participant systems include:
- Event Definitions: We provide content for multiple crises, including wildfires, hurricanes and flood events. The following is an example event definition:
{
"eventID": "CrisisFACTS-001",
"trecisId": "TRECIS-CTIT-H-092",
"dataset": "2017_12_07_lilac_wildfire.2017",
"title": "Lilac Wildfire 2017",
"type": "Wildfire",
"url": "https://en.wikipedia.org/wiki/Lilac Fire",
"description": "The Lilac Fire was a fire that burned in northern San Diego County, California, United States, and the second-costliest one one of multiple of multiple wildfires that erupted in Southern California in December 2017."
}
Fig 2. Example Event Definition for the 2017 Lilac Fire
- User Profiles: The itemised list of general and event-type-specific queries representing a responder’s information needs. These queries provide a method for filtering disaster-related content to only ICS-related facts. We also include TREC-IS category mappings for each query. Example queries include:
[{
"queryID": "CrisisFACTS-General-q001",
"indicativeTerms": "airport closed",
"query": "Have airports closed",
"trecisCategoryMapping": "Report-Factoid"
},
{
"queryID": "CrisisFACTS-General-q002",
"indicativeTerms": "rail closed",
"query": "Have railways closed",
"trecisCategoryMapping": "Report-Factoid"
},
{
"queryID": "CrisisFACTS-General-q003",
"indicativeTerms": "water supply",
"query": "Have water supplies been contaminated",
"trecisCategoryMapping": "Report-EmergingThreats"
},
...,
{
"queryID": "CrisisFACTS-Wildfire-q001",
"indicativeTerms": "acres size",
"query": "What area has the wildfire burned",
"trecisCategoryMapping": "Report-Factoid"
},
{
"queryID": "CrisisFACTS-Wildfire-q002",
"indicativeTerms": "wind speed",
"query": "Where are wind speeds expected to be high",
"trecisCategoryMapping": "Report-Weather"
},
...
]
Fig 3. Example Query Definition
- Summary Requests: Each request lists the event ID, date to summarise, and the start and end timestamps bounding the requested summary. A multi-day disaster will have multiple such summary requests:
[{
"eventID": "CrisisFACTS-001",
"requestID": "CrisisFACTS-001-r3",
"dateString": "2017-12-07",
"startUnixTimestamp": 1512604800,
"endUnixTimestamp": 1512691199
},
...,
{
"eventID": "CrisisFACTS-001",
"requestID": "CrisisFACTS-001-r4",
"dateString": "2017-12-08",
"startUnixTimestamp": 1512691200,
"endUnixTimestamp": 1512777599
}]
Fig 4. Example Summary Requests
- Content Streams: A set of content snippets from online streams. Each snippet is approximately a sentence in length and may not be relevant to the event–i.e., content streams are noisy. Each snippet has an associated event ID, stream identifier (CrisisFACTS-Event ID-Stream Name-Stream ID-Snippet), source, timestamp and a piece of text. Your summary should be built from these items.
[{
"event": "CrisisFACTS-001",
"streamID": "CrisisFACTS-001-Twitter-14023-0",
"unixTimestamp": 1512604876,
"text": "Big increase in the wind plus drop in humidity tonight into Thursday for San Diego County #SanDiegoWX https://t.co/1pV0ZAhsJH",
"sourceType": "Twitter"
},
{
"event": "CrisisFACTS-001",
"streamID": "CrisisFACTS-001-Twitter-27052-0",
"unixTimestamp": 1512604977,
"text": "Prayers go out to you all! From surviving 2 massive wild fires in San Diego and California in general we have all c… https://t.co/B5Y7KLY0uS",
"sourceType": "Twitter"
},
{
"event": "CrisisFACTS-001",
"streamID": "CrisisFACTS-001-Twitter-43328-0",
"unixTimestamp": 1512691164,
"text": "If you're in the San Diego area (or north of it), you should probably turn on tweet notifs from @CALFIRESANDIEGO fo… https://t.co/hNjEuEfKaB",
"sourceType": "Twitter"
}]
Fig 5. Three Event Snippets for Event CrisisFACTS-001
System Output
Your system should produce one summary for each event-day request using the content provided for that event-day and posted between the event-day starting and ending timestamps.
This task differs from traditional summarization in that you should not simply produce a block of text of a set length. Instead, this track’s daily “summaries” contain sets of facts describing the target disaster’s evolution. Your summaries should contain ‘facts’ that match one or more of the queries outlined in User Profiles.
For evaluation, CrisisFACTS organizers will use the top-k “most important” facts from a given event-day pair as the summary for that event-day.
Each fact should contain the following:
Required:
- RequestID: The identifier of the summary request.
- Fact Text: A short single-sentence statement that conveys an important, atomic and self-contained piece of information about the event.
- Timestamp: A UNIX epoch timestamp indicating the earliest point in time that your system detected the fact.
- Importance: A numerical score between 0 and 1 that indicates how important your system thinks it is for this fact to be included in the final summary. Evaluation will use this value to rank your facts, taking the top-k as the summary.
- Sources: A list of StreamID identifiers that your system believes support the fact (what you used as input to produce the fact text).
Optional:
- StreamID: If your system is extractive (i.e., your facts are direct copies of text found in the input streams), include the
StreamIDof your fact’s original item. - InformationNeeds: If your system directly uses the queries/information-needs to decide what to include in your summary, and these can act as an explanation for what your system included an item, then list the queries that were core to this item’s selection.
Output Examples
Example Abstractive Output
Examples of system output are as follows:
{
"requestID": "CrisisFACTS-001-r3",
"factText": "Increased threat of wind damage in the San Diego area.",
"unixTimestamp":1512604876,
"importance": 0.71,
"sources": [
"CrisisFACTS-001-Twitter-14023-0"
],
"streamID": null,
"informationNeeds": ["CrisisFACTS-General-q015"]
}
...
Fig 6. Example System Output with Abstractive Facts. The streamID field is empty as this fact may not appear in the dataset verbatim. It is, however, supported by one Twitter message.
Example Extractive Output
{
"requestID": "CrisisFACTS-001-r3",
"factText": "Big increase in the wind plus drop in humidity tonight into Thursday for San Diego County #SanDiegoWx https://t.co/1pVOZAhsJH",
"unixTimestamp":1512604876,
"importance": 0.71,
"sources": [
"CrisisFACTS-001-Twitter-14023-0"
],
"streamID": "CrisisFACTS-001-Twitter-14023-0",
"informationNeeds": ["CrisisFACTS-General-q015"]
}
...
Fig 7. Example System Output with Extractive Facts. The streamID field is populated with the Twitter document from which this text was taken.
Other Output Details
Participant systems may produce as many facts as they wish for a specific summary request. However, to handle variable summary length, each fact may not contain more than 200 characters.
For days after the first, your system should avoid returning information that has been reported in previous summaries for the same event. Furthermore, evaluation will be performed at a predetermined number of facts (not revealed in advance). To truncate your list of facts, we will rank them by importance score and cut at a specific rank k – which will vary across event-day pairs.
We recommend that you return at least 100 facts per summary request.
Datasets and Sources
Disaster Data Streams
For each day during an event, the following content is available:
- Twitter Stream: We are re-using tweets collected as part of the TREC Incident Streams track (http://trecis.org). These tweets were crawled by keyword, should be relevant to the event (though some noise likely exists), but are not necessarily good candidates for inclusion into a summary of what is happening.
- Reddit Stream: We have collected relevant Reddit threads to each event, where we include both the original submission and subsequent comments within those threads. These streams are built from relevant top-level posts with all comments associated with the post, so some comments may not be informative.
- Facebook Stream: We provide Facebook/Meta posts from public pages that are relevant to each event using CrowdTangle. While we cannot share the text content of these posts directly, we have included the post and page IDs of this content within the stream. This data can then be re-collected manually.
- News Stream: Traditional news agencies are often a good source of information during an emergency, and we have included a small number of news articles collected during each event as well.
Accessing the Data
CrisisFACTS has transitioned to the ir_datasets infrastructure for making data available to the community. We provide a GitHub repository with Jupyter notebooks and a Collab notebook to accelerate participants’ access to this data:
Disaster Events
2022 Training Events
The eight events from 2022 are listed below. Gold-standard fact-lists from these events are available here.
| eventID | Title | Type | Tweets | News | ||
|---|---|---|---|---|---|---|
| CrisisFACTS-001 | Lilac Wildfire 2017 | Wildfire | 41,346 | 1,738 | 2,494 | 5,437 |
| CrisisFACTS-002 | Cranston Wildfire 2018 | Wildfire | 22,974 | 231 | 1,967 | 5,386 |
| CrisisFACTS-003 | Holy Wildfire 2018 | Wildfire | 23,528 | 459 | 1,495 | 7,016 |
| CrisisFACTS-004 | Hurricane Florence 2018 | Hurricane | 41,187 | 120,776 | 18,323 | 196,281 |
| CrisisFACTS-005 | Maryland Flood 2018 | Flood | 33,584 | 2,006 | 2,008 | 4,148 |
| CrisisFACTS-006 | Saddleridge Wildfire 2019 | Wildfire | 31,969 | 244 | 2,267 | 3,869 |
| CrisisFACTS-007 | Hurricane Laura 2020 | Hurricane | 36,120 | 10,035 | 6,406 | 9,048 |
| CrisisFACTS-008 | Hurricane Sally 2020 | Hurricane | 40,695 | 11,825 | 15,112 | 48,492 |
Image Data
Below, we make a selection images available for use that are associated with each of these events. You can download the raw images, dense embeddings of these images using ConvNeXt, and CSV files connecting embeddings to the specific image.
Using labels from TREC-IS, we also provide a subset of images from messages that have been annotated as high- or critical-priority or from an actionable information type.
| CrisisFACTS ID | TREC-IS ID | Filtered Image Data | High-Priority Image Data |
|---|---|---|---|
| CrisisFACTS-001 | TRECIS-CTIT-H-092 | Filtered Images, Embeddings, csv | High-Priority Images, Embeddings, csv |
| CrisisFACTS-002 | TRECIS-CTIT-H-095 | Filtered Images, Embeddings, csv | |
| CrisisFACTS-003 | TRECIS-CTIT-H-097 | Filtered Images, Embeddings, csv | |
| CrisisFACTS-004 | TRECIS-CTIT-H-098 | Filtered Images, Embeddings, csv | High-Priority Images, Embeddings, csv |
| CrisisFACTS-005 | TRECIS-CTIT-H-101 | Filtered Images, Embeddings, csv | High-Priority Images, Embeddings, csv |
| CrisisFACTS-006 | TRECIS-CTIT-H-106 | Filtered Images, Embeddings, csv | |
| CrisisFACTS-007 | TRECIS-CTIT-H-113 | Filtered Images, Embeddings, csv | |
| CrisisFACTS-008 | TRECIS-CTIT-H-114 | Filtered Images, Embeddings, csv |
2023 New Events
| eventID | Title | Type | Tweets | News | ||
|---|---|---|---|---|---|---|
| CrisisFACTS-009 | Beirut Explosion, 2020 | Accident | 94,892 | 3,257 | 1,163 | 368,866 |
| CrisisFACTS-010 | Houston Explosion, 2020 | Accident | 58,370 | 5,704 | 2,175 | 6,281 |
| CrisisFACTS-011 | Rutherford TN Floods, 2020 | Floods | 11,019 | 475 | 268 | 9,116 |
| CrisisFACTS-012 | TN Derecho, 2020 | Storm/Flood | 49,247 | 1,496 | 15,425 | 13,521 |
| CrisisFACTS-013 | Edenville Dam Fail, 2020 | Accident | 16,527 | 2,339 | 961 | 8,358 |
| CrisisFACTS-014 | Hurricane Dorian, 2019 | Hurricane | 86,915 | 91,173 | 7,507 | 370,644 |
| CrisisFACTS-015 | Kincade Wildfire, 2019 | Wildfire | 91,548 | 10,174 | 339 | 35,011 |
| CrisisFACTS-016 | Easter Tornado Outbreak, 2020 | Tornadoes | 91,812 | 5,070 | 750 | 34,343 |
| CrisisFACTS-017 | Tornado Outbreak, 2020 Apr | Tornadoes | 99,575 | 1,233 | 217 | 19,878 |
| CrisisFACTS-018 | Tornado Outbreak, 2020 March | Tornadoes | 95,221 | 16,911 | 641 | 87,242 |
Image Data
As above, , we make a selection images available for use that are associated with each of these events.
| CrisisFACTS ID | TREC-IS ID | Filtered Image Data | High-Priority Image Data |
|---|---|---|---|
| CrisisFACTS-009 | TRECIS-CTIT-H-066 | Filtered Images, Embeddings, csv | High-Priority Images, Embeddings, csv |
| CrisisFACTS-010 | TRECIS-CTIT-H-076 | Filtered Images, Embeddings, csv | High-Priority Images, Embeddings, csv |
| CrisisFACTS-011 | TRECIS-CTIT-H-079 | Filtered Images, Embeddings, csv | |
| CrisisFACTS-012 | TRECIS-CTIT-H-083 | Filtered Images, Embeddings, csv | High-Priority Images, Embeddings, csv |
| CrisisFACTS-013 | TRECIS-CTIT-H-084 | Filtered Images, Embeddings, csv | |
| CrisisFACTS-014 | TRECIS-CTIT-H-104 | Filtered Images, Embeddings, csv | |
| CrisisFACTS-015 | TRECIS-CTIT-H-107 | Filtered Images, Embeddings, csv | High-Priority Images, Embeddings, csv |
| CrisisFACTS-016 | TRECIS-CTIT-H-116 | Filtered Images, Embeddings, csv | High-Priority Images, Embeddings, csv |
| CrisisFACTS-017 | TRECIS-CTIT-H-119 | Filtered Images, Embeddings, csv | High-Priority Images, Embeddings, csv |
| CrisisFACTS-018 | TRECIS-CTIT-H-120 | Filtered Images, Embeddings, csv |
Submissions
Runs will be submitted through the NIST submission system at trec.nist.gov. Runs that do not pass validation will be rejected outright. Submitted runs will be asked to specify the following:
- Whether they are (a) manual or automatic,
- Whether they use (b) extant TREC-IS labels for Twitter data, and
- Whether the summaries built are (c) abstractive or extractive.
Automatic Runs
Each run submission must indicate whether the run is manual or automatic. An automatic run is any run that receives no human intervention once the system is started and provided with the task inputs. We expect most CrisisFACTS runs to be automatic.
Manual Runs
Results on manual runs will be specifically identified when results are reported. A manual run is any run in which a person manually changes, summarises, or re-ranks queries, the system, or the system’s lists of facts. Simple bug fixes that address only format handling do not result in manual runs, but the changes should be described.
Submission Format
The submission format for CrisisFACTS is a newline-delimited JSON file, where each entry in the submitted file contains the fields outlined in System Output section above. Each submission file corresponds to a single submitted run (i.e., all event-day pairs for all events), with the submission’s runtag included in the filename.
Example submissions are available in Output Examples.
Evaluation
As in 2022, participant runs will be evaluated on two approaches. In both approaches, participant systems’ lists of facts will be truncated to a private k value based on NIST assessors’ results.
Metric Set 1 – ROUGE-based Summarization Against Daily Summaries
- Top facts for each event-day pair will be aggregated into a “summary” of that day’s developments as a single document. This summary will be compared against extant summaries via ROUGE-x, BERTScore, and similar.
- Gold-standard summaries include:
- NIST-based assessments of these events and related summaries
- Summaries extracted from the ICS209 reports from FEMA, when available
Metric Set 2 – Individual Fact-Matching Between Runs and Manual Fact Lists
- First, NIST assessors will construct a set of facts for each event-day pair from a pooled set of facts from all participant runs.
- After constructing this fact list, assessors will match output from participant runs to each of these facts to assess comprehensiveness and redundancy ratio, which act as proxies for recall and precision respectively.
- For a given event-day pair, we therefore have:
- A set of “gold standard” facts $S$ produced by NIST assessors
- A set of submitted facts $f \in F$ from a participant run
- A fact-matching function $M(F, S)$ that measures the overlap between submitted facts $F$ and the gold-standard fact set $S$.
- Using this fact-matching function, we define comprehensiveness (a recall-oriented metric):
- $C(F, S) = \frac{M(F, S)}{|S|}$
- We likewise define redundancy as the number of submitted facts that match a gold-standard fact (i.e., precision):
- $R(F, S) = \frac{M(F, S)}{|F|}$
- For each disaster event, we calculate the average comprehensiveness and redundancy scores over all days in the event where $S$ contains facts.
Timeline
| Milestone | Date |
|---|---|
| Guidelines released | 10 May 2023 |
| Submissions Due | 1 September 2023 |
| NIST-Assessor Evaluation | 5-22 September 2023 |
| Scores returned to participants | 29 September 2022 |
| TREC Notebook Drafts Due | 7 November 2023 (Tentative) |
| TREC Conference | 15-17 November 2023 (Tentative) |
Organizers

Cody Buntain
@cbuntain
he/him
College of Information Studies, University of Maryland, College Park.

Benjamin Horne
@benjamindhorne
he/him
University of Tennessee–Knoxville.

Amanda Hughes
@PIOResearcher
she/her
Brigham Young University.

Muhammad Imran
@mimran15
he/him
Qatar Computing Research Institute.

Richard McCreadie
@richardm_
he/him
School of Computing Science, University of Glasgow.

Hemant Purohit
@hemant_pt
he/him
George Mason University.